How can robots learn from watching humans?
The robot first observes human videos and extracts visual priors, such as information about hand-object interactions and hand motion. We project these into a simple set of robot primitives (grasp location, orientation and force as well as trajectory waypoints). These primitives are executed by the robot in the real world. We use off-the-shelf 3D Computer Vision models, which can have inaccuracies. Therfore, when the robot executes these in the real world, it is likely to be close but fail. So the question is how can the robot actually improve? We need to use the human video to guide the improvement.
How can we compare human and robot videos?
Consider these drawer opening videos: we can't naively compare human and robot videos well in feature or pixel space since there is a large embodiment gap. However, if we were to remove the agent from the scene, we could in fact perform a meaningful comparison. Thus, we use an off-the-shelf inpainting method to remove the agents. Using the inpainted videos, we build an agent-agnostic cost function to efficiently improve the policy in the real world.
WHIRL: In-the-Wild Human Imitating Robot Learning
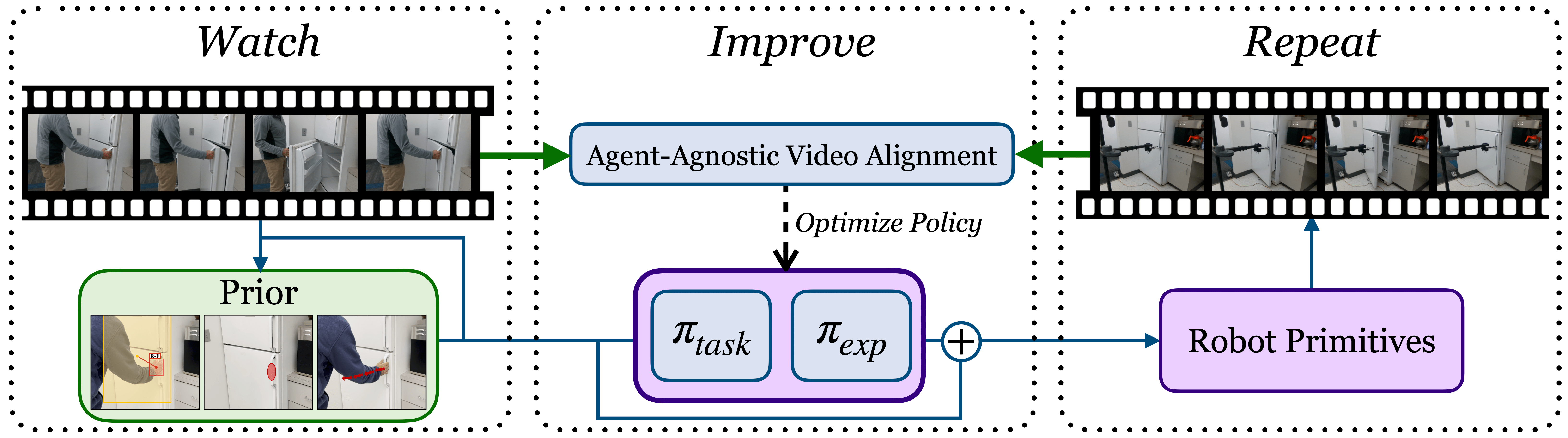
Our method, WHIRL, provides an efficient way to learn from human videos. We have three core components: we first watch and obtain human priors such as hand movement and object interactions. We repeat these priors by interacting in the real world, by both trying to achieve task success and explore around the prior. We improve our task policy by leveraging our agent-agnostic objective function which aligns human and robot videos.
Training Procedure
Task Videos
We perform 20 different tasks in the wild, where input to the robot is a single human video. For each of these, WHIRL is trained for 1-2 hours.
Numerical Results
We compare WHIRL against state-of-the-art baselines, and see a strong performance boost from our approach. We find that all components of WHIRL, for example the iterative improvement, the agent agnostic cost function and the exploration policy, are important. From the plots, we see that success improves with more interactions with the real world.
In the Media
Spotlight Talk
Code and Dataset
We provide a paired human-to-robot Dataset (on google drive). This dataset contains videos of 20 different tasks obtained from running WHIRL.
BibTeX
@inproceedings{bahl2022human,
title={Human-to-Robot Imitation in the Wild},
author={Bahl, Shikhar and Gupta, Abhinav and Pathak, Deepak},
journal={RSS},
year={2022}
}Acknowledgements
We thank Jason Zhang, Yufei Ye, Aravind Sivakumar, Sudeep Dasari and Russell Mendonca for very fruitful discussions and are grateful to Ananye Agarwal, Alex Li, Murtaza Dalal and Homanga Bharadhwaj for comments on early drafts of this paper. AG was supported by ONR YIP. The work was supported by Samsung GRO Research Award, NSF IIS-2024594 and ONR N00014-22-1-2096.